


Abstract
There is immense hyperbole about recent developments in artificial intelligence, especially Large Language Models like ChatGPT. And there is also deserved concern about such technologies’ material impact on jobs. But observers are missing two very important things:
Every wave of technological innovation has been unleashed by something costly becoming cheap enough to waste.
Software production has been too complex and expensive for too long, which has caused us to underproduce software for decades, resulting in immense, society-wide technical debt.
This technical debt is about to contract in a dramatic, economy-wide fashion as the cost and complexity of software production collapses, releasing a wave of innovation.
*****************
Software is misunderstood. It can feel like a discrete thing, something with which we interact. But, really, it is the intrusion into our world of something very alien. It is the strange interaction of electricity, semiconductors, and instructions, all of which somehow magically control objects that range from screens to robots to phones, to medical devices, laptops, and a bewildering multitude of other things. It is almost infinitely malleable, able to slide and twist and contort itself such that, in its pliability, it pries open doorways as yet unseen.
This sense of the alien-other nature of software has bubbled up to the surface of public consciousness recently, as truly conversational artificial intelligence—based on Large Language Models (LLMs), such as ChatGPT—have gone from the stuff of science fiction to something that people can play with as easily as they can search the internet.
Why Hasn’t Software Eaten the World?
This can feel reminiscent of Marc Andreessen’s line from the last tech cycle, that “software is eating the world.” And while Marc’s line is a useful way of thinking about software’s appetites, it is worth wondering why software is taking so damn long to finish eating. And, further, if it were to really get to feasting, what would be the catalyst or catalysts, and what would that software-eaten world look like?
To answer these questions, we must look back before we look forward. In doing so, we will consider a range of factors, including complexity, factor costs, and economic models of software supply and demand.
Let’s start by considering an economic model of software supply and demand. Software has a cost, and it has markets of buyers and sellers. Some of those markets are internal to organizations. But the majority of those markets are external, where people buy software in the form of apps, or cloud services, or games, or even embedded in other objects that range from Ring doorbells to endoscopic cameras for cancer detection. All of these things are software in a few of its myriad forms.
With these characteristics in mind, you can think of software in a basic price/quantity graph from introductory economics. There is a price and a quantity demanded at that price, and there is a price and quantity at which those two things are in rough equilibrium, as the following figure shows. Of course, the equilibrium point can shift about for many reasons, causing the P/Q intersection to be at higher or lower levels of aggregate demand. If the price is too high we underproduce software (leaving technical debt), and if too low, well … let’s come back to that.

This leads us to a basic question that sometimes gets asked in economics classes: How do we know this combinate of price and quantity is the optimal one? The orthodox answer is that if the the supply and demand lines are correct, then it must be the right one, given the downward-sloping demand (people want less of most things when the price goes up), and the upward-sloping supply (manufacturers supply more of a thing when the price goes up). When we go past where those two lines intersect, every increment in price might make manufacturers want to produce more, but leave buyers wanting less, so you end up with excessive inventories or prices crashes, or both. And, in reverse, when the price falls, manufacturers want to produce less, even if buyers want more, which leads to scarcity, and, in turn, often drives prices higher again until supply and demand equilibrate.
How Technology Confounds Economics
This is all straightforward undergraduate economics. But technology has a habit of confounding economics. When it comes to technology, how do we know those supply and demand lines are right? The answer is that we don’t. And that’s where interesting things start happening.
Sometimes, for example, an increased supply of something leads to more demand, shifting the curves around. This has happened many times in technology, as various core components of technology tumbled down curves of decreasing cost for increasing power (or storage, or bandwidth, etc.). In CPUs, this has long been called Moore’s Law, where CPUs become more powerful by some increment every 18 months or so. While these laws are more like heuristics than F=ma laws of physics, they do help as a guide toward how the future might be different from the past.
We have seen this over and over in technology, as various pieces of technology collapse in price, while they grow rapidly in power. It has become commonplace, but it really isn’t. The rest of the economy doesn’t work this way, nor have historical economies. Things don’t just tumble down walls of improved price while vastly improving performance. While many markets have economies of scale, there hasn’t been anything in economic history like the collapse in, say, CPU costs, while the performance increased by a factor of a million or more.
To make this more palpable, consider that if cars had improved at the pace computers have, a modern car would:
Have more than 600 million horsepower
Go from 0-60 in less than a hundredth of a second
Get around a million miles per gallon
Cost less than $5,000
And they don’t. Sure, Tesla Plaid is a speedy car, it is nowhere near the above specs—no car ever will be. This sort of performance inflection is not our future, but it fairly characterizes and even understates what has happened in technology over the last 40 years. And yet, most people don’t even notice anymore. It is just commonplace, to the point that our not noticing is staggering.
The Collapse Dynamic in Technology
You can see these dynamics in the following graph. Note the logarithmic scale on the Y-axis, which prevents the price/performance lines from being vertical—that is how quickly and sharply the price per unit performance of all these factors have fallen. It is unprecedented in economic history.
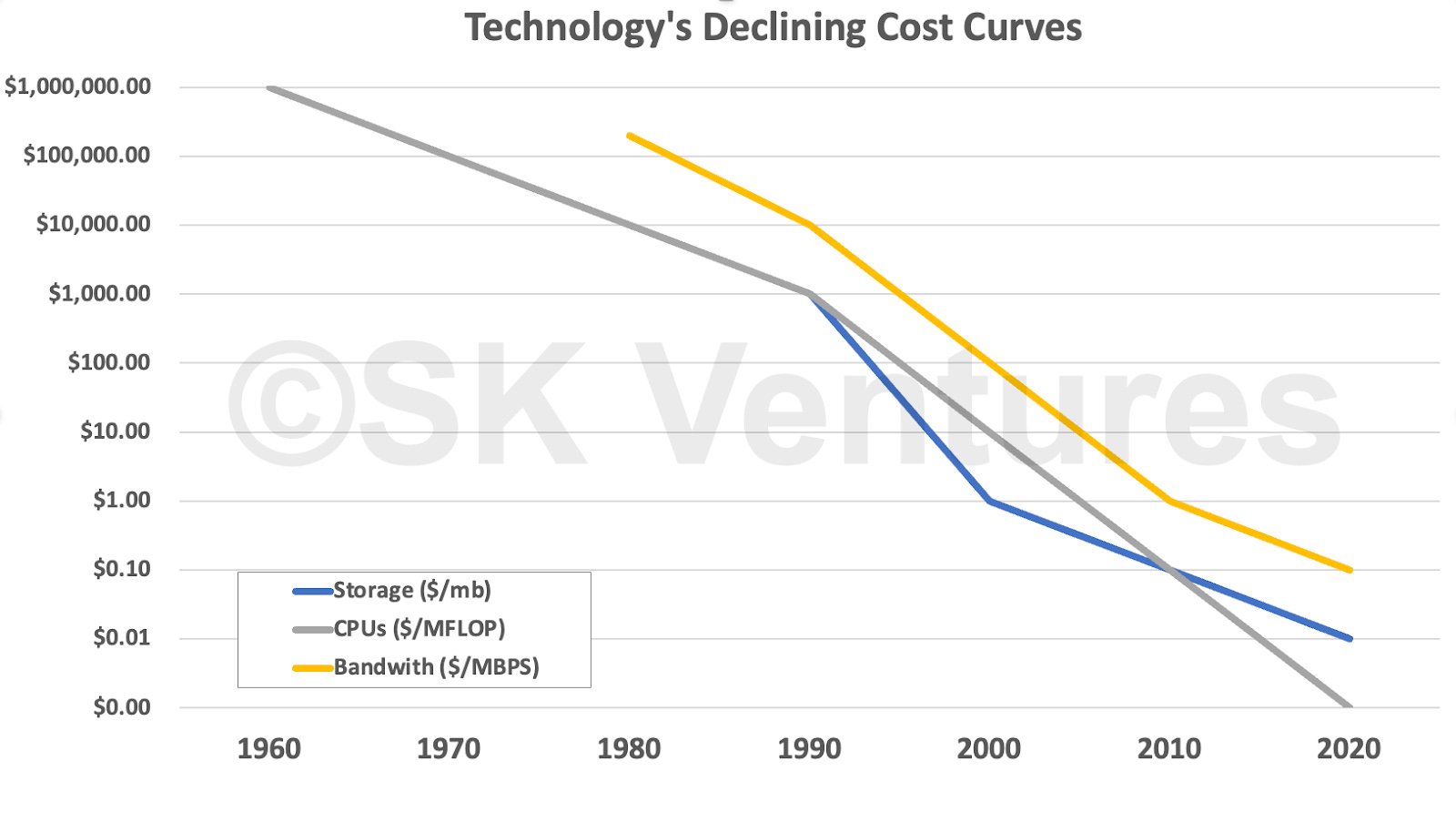
And each of these collapses has had broader consequences. The collapse of CPU prices led us directly from mainframes to the personal computer era; the collapse of storage prices (of all kinds) led inevitably to more personal computers with useful local storage, which helped spark databases and spreadsheets, then led to web services, and then to cloud services. And, most recently, the collapse of network transit costs (as bandwidth exploded) led directly to the modern Internet, streaming video, and mobile apps.
In a kind of reversal of the old Paul Simon song (“The Boy in the Bubble”), every technology generation throws a hero down the pop (or, price per unit performance) charts. Each collapse, with its accompanying performance increases, sparks huge winners and massive change, from Intel, to Apple, to Akamai, to Google & Meta, to the current AI boomlet. Each beneficiary of a collapse requires one or more core technologies' price to drop and performance to soar. This, in turn, opens up new opportunities to “waste” them in service of things that previously seemed impossible, prohibitively expensive, or both.
AI as the Next Collapse Dynamic in Technology
All of that brings us to today. Suddenly AI has become cheap, to the point where people are “wasting” it via “do my essay” prompts to chatbots, getting help with microservice code, and so on. You could argue that the price/performance of intelligence itself is now tumbling down a curve, much like as has happened with prior generations of technology.
You could argue that, but it’s too narrow and orthodox a view, or at the very least, incomplete and premature. Set aside the ethics and alignment issues of artificial general intelligence (AGI). It is likely still years away, at best, even if it feels closer than it has in decades. In that light, it’s worth reminding oneself that waves of AI enthusiasm have hit the beach of awareness once every decade or two, only to recede again as the hyperbole outpaces what can actually be done. We saw this in the 1950s with Minsky’s (failed) work, again in the 1970s with Japan’s (failed) Fifth Generation Project, and again in the 2000s with IBM’s (failed) Watson. If you squint really hard, you might see a pattern.
Still, the suddenly emergent growth of LLMs has some people spending buckets of time thinking about what service occupations can be automated out of existence, what economists called “displacement” automation. It doesn’t add much to the aggregate store of societal value, and can even be subtractive and destabilizing, a kind of outsourcing-factory-work-to-China moment for white-collar workers. Perhaps we should be thinking less about opportunities for displacement automation and more about opportunities for augmenting automation, the kind of thing that unleashes creativity and leads to wealth and human flourishing.
So where will that come from? We think this augmenting automation boom will come from the same place as prior ones: from a price collapse in something while related productivity and performance soar. And that something is software itself.
By that, we don’t literally mean “software” will see price declines, as if there will be an AI-induced price war in word processors like Microsoft Word, or in AWS microservices. That is linear and extrapolative thinking. Having said that, we do think the current frenzy to inject AI into every app or service sold on earth will spark more competition, not less. It will do this by raising software costs (every AI API call is money in someone’s coffers), while providing no real differentiation, given most vendors will be relying on the same providers of those AI API calls.
Baumol’s Cost Disease and the Trouble with Software
Understanding what we do mean requires a brief return to some basic economics. Most of us are familiar with how the price of technology products has collapsed, while the costs of education and healthcare are soaring. This can seem a maddening mystery, with resulting calls to find new ways to make these industries more like tech, by which people generally mean more prone to technology’s deflationary forces.
But this is a misunderstanding. To explain: In a hypothetical two-sector economy, when one sector becomes differentially more productive, specialized, and wealth-producing, and the other doesn’t, there is huge pressure to raise wages in the latter sector, lest many employees leave. Over time that less productive sector starts becoming more and more expensive, even though it’s not productive enough to justify the higher wages, so it starts “eating” more and more of the economy.
Economist William Baumol is usually credited with this insight, and for that it is called Baumol’s cost disease. You can see the cost disease in the following figure, where various products and services (spoiler: mostly in high-touch, low-productivity sectors) have become much more expensive in the U.S., while others (non-spoiler: mostly technology-based) have become cheaper. This should all make sense now, given the explosive improvements in technology compared to everything else. Indeed, it is almost a mathematical requirement.
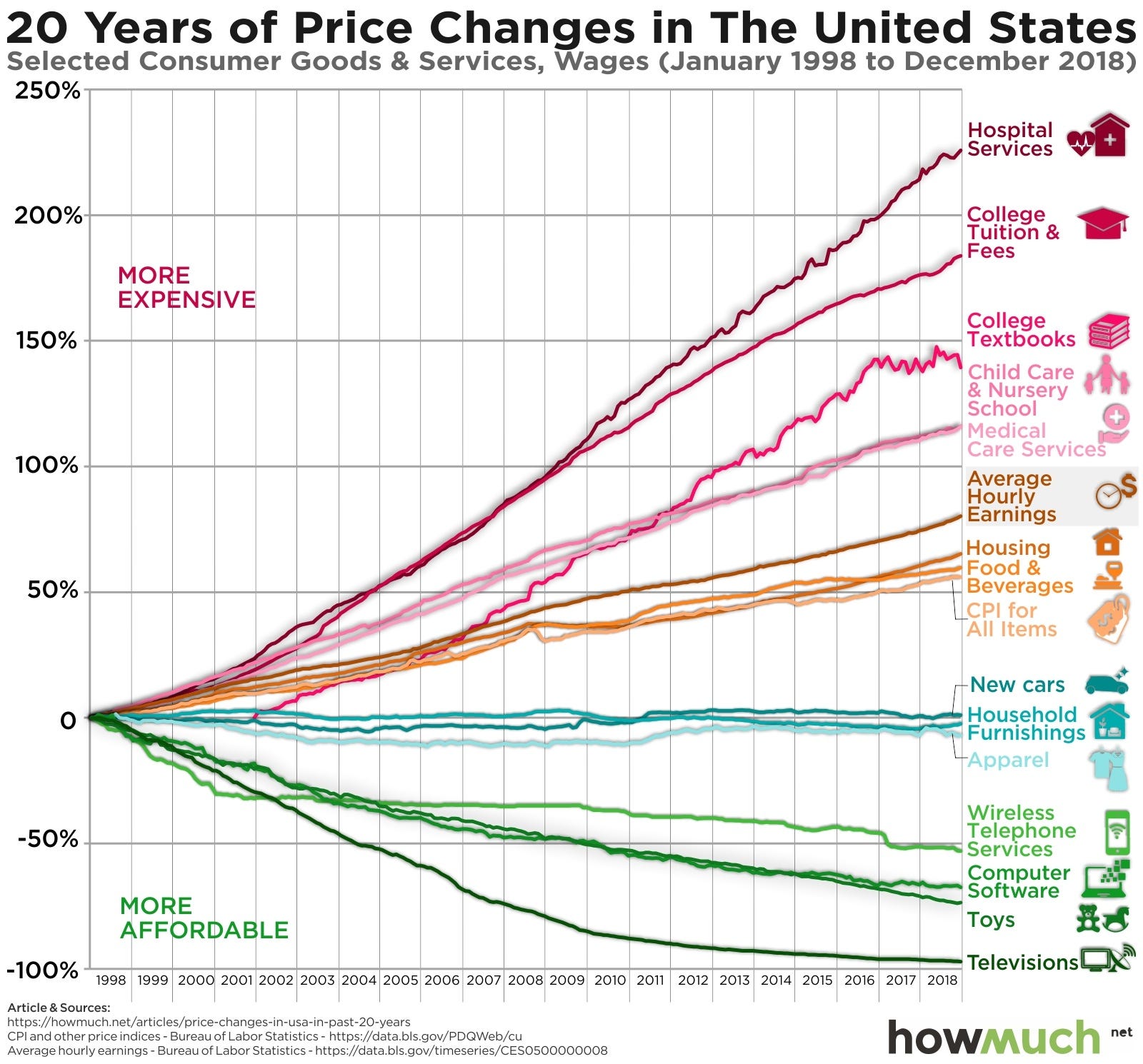
Absent major productivity improvements, which can only come from eliminating humans from these services, it is difficult to imagine how this changes. It is more likely to continue getting worse, assuming we want healthcare and education in the future, given most value in these services will continue to be delivered by humans.
But there is another sector being held back by a variant of Baumol’s cost disease, and that is software itself. This may sound contradictory, which is understandable. After all, how can the most productive, wealth-generating, deflationary sector also be the victim of the same malaise it is inflicting on other sectors?
It can, if you think back to the two-sector model we discussed earlier. One sector is semis and CPUs, storage and backbone networks. Those prices are collapsing, requiring fewer people while producing vastly more performance at lower prices. Meanwhile, software is chugging along, producing the same thing in ways that mostly wouldn’t seem vastly different to developers doing the same things decades ago. Yes, there have been developments in the production and deployment of software, but it is still, at the end of the day, hands pounding out code on keyboards. This should seem familiar, and we shouldn’t be surprised that software salaries stay high and go higher, despite the relative lack of productivity. It is Baumol’s cost disease in a narrow, two-sector economy of tech itself.
These high salaries play directly into high software production costs, as well as limiting the amount of software produced, given factor production costs and those pesky supply curves. Startups spend millions to hire engineers; large companies continue spending millions keeping them around. And, while markets have clearing prices, where supply and demand meet up, we still know that when wages stay higher than comparable positions in other sectors, less of the goods gets produced than is societally desirable. In this case, that underproduced good is…software. We end up with a kind of societal technical debt, where far less is produced than is socially desirable—we don’t know how much less, but it is likely a very large number and an explanation for why software hasn’t eaten much of the world yet. And because it has always been the case, no-one notices.
Demographics, Aging, and the Coming Labor Disruption from LLMs
We think that’s all about to change. The current generation of AI models are a missile aimed, however unintentionally, directly at software production itself. Sure, chat AIs can perform swimmingly at producing undergraduate essays, or spinning up marketing materials and blog posts (like we need more of either), but such technologies are terrific to the point of dark magic at producing, debugging, and accelerating software production quickly and almost costlessly.
And why shouldn’t it be? As the following figure shows, Large Language Model (LLM) impacts in the job market can be thought of as a 2x2 matrix. Along one axis we have how grammatical the domain is, by which we mean how rules-based are the processes governing how symbols are manipulated. Essays, for example, have rules (ask any irritated English teacher), so chat AIs based on LLMs can be trained to produce surprisingly good essays. Tax providers, contracts, and many other fields are in this box too.

The resulting labor disruption is likely to be immense, verging on unprecedented, in that top-right quadrant in the coming years. We could see millions of jobs replaced across a swath of occupations, and see it happen faster than in any previous wave of automation. The implications will be myriad for sectors, for tax revenues, and even for societal stability in regions or countries heavily reliant on some of those most-affected job classes. These broad and potentially destabilizing impacts should not be underestimated, and are very important.
Some argue that the demographics of an aging society and inverting population pyramids in developed economies will counterbalance these AI-induced changes. While demographics will soften the blow in the coming decades—an aging society and a shrinking workforce in parts of the world will be desperate for labor— those demographic forces are unlikely to be enough. These changes are so important that we will return to this topic in a future missive.
Software is at the Epicenter of its Own Disruption
For now, however, let’s turn back to software itself. Software is even more rule-based and grammatical than conversational English, or any other conversational language. Programming languages—from Python to C++—can be thought of as formal languages with a highly explicit set of rules governing how every language element can and cannot be used to produce a desired outcome. Programming languages are the naggiest of grammar nags, which is intensely frustrating for many would-be coders (A missing colon?! That was the problem?! Oh FFS!), but perfect for LLMs like ChatGPT.
The second axis in this figure is equally important. In addition to the underlying grammar, there is also the predictability of the domain. Does the same cause always lead to the same effect? Or is the domain more ad hoc, with causes sometimes preceding effects, but not always, and not predictably.
Again, programming is a good example of a predictable domain, one created to produce the same outputs given the same inputs. If it doesn’t do that, that’s 99.9999% likely to be on you, not the language. Other domains are much less predictable, like equity investing, or psychiatry, or maybe, meteorology.
This framing—grammar vs predictability—leaves us convinced that for the first time in the history of the software industry, tools have emerged that will radically alter the way we produce software. This isn’t about making it easier to debug, or test, or build, or share—even if those will change too—but about the very idea of what it means to manipulate the symbols that constitute a programming language.
Let’s get specific. Rather than having to learn Python to parse some text and remove ASCII emojis, for example, one could literally write the following ChatGPT prompt:
Write some Python code that will open a text file and get rid of all the emojis, except for one I like, and then save it again.
In case you’re thinking, “there’s no way that works,” you’re wrong. It works fine, took two seconds, and is just a glimpse of how previously inaccessible deftness at writing code is now available to anyone:
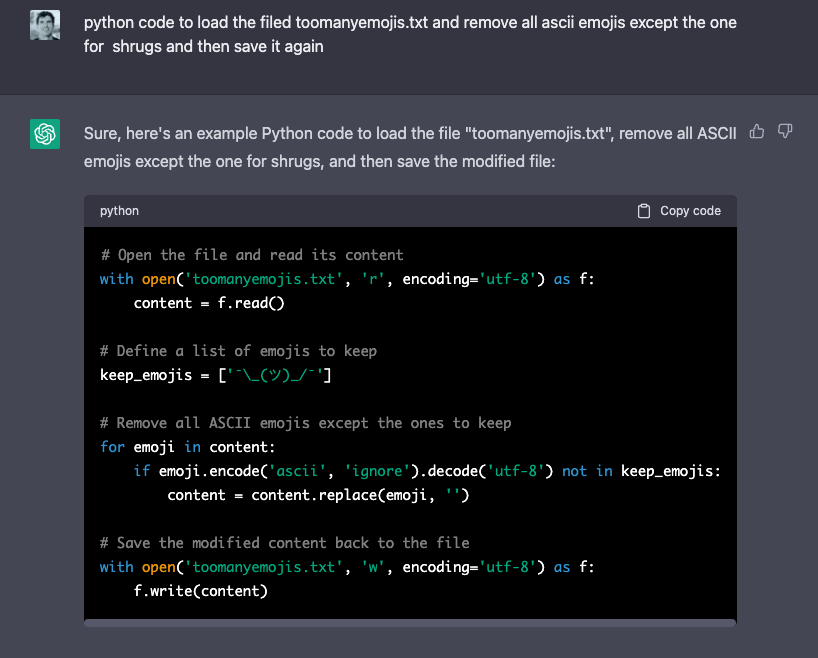
To state the obvious: This is a trivial, boring and stupid example, even if it is useful in the right emoji-laden circumstances. It’s not complex code. It is simple to the point of being annoying for skilled practitioners, while simultaneously impossible for most other people, absent many Reddit and Quora visits.
But it gets better and deeper. Say you weren’t sure why this works, or were skeptical that it would work, and thought maybe the AI was bluffing. You could ask it to explain itself, as shown here:
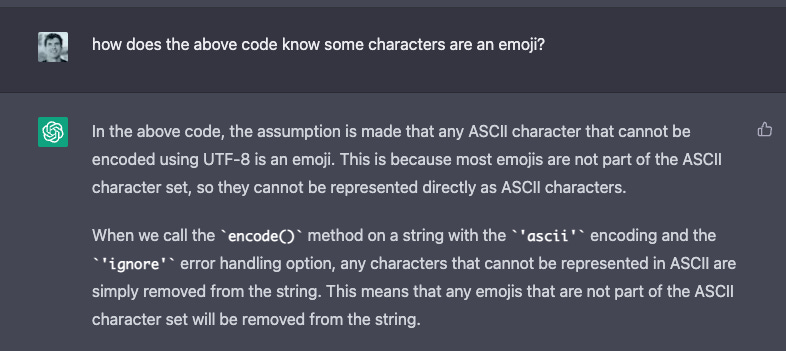
In short, the LLM used a neat hack. Instead of working through an exhaustive list of all ASCII emojis and seeing if they’re present, it elected to use character encodings to differentiate emojis from non-. That is damn clever, and that you can ask the LLM to explain how it did something—that there is a self-referential explanatory power—is another reason why this changes the software game.
This is just the beginning (and it will only get better). It’s possible to write almost every sort of code with such technologies, from microservices joining together various web services (a task for which you might previously have paid a developer $10,000 on Upwork) to an entire mobile app (a task that might cost you $20,000 to $50,000 or more).
What Cheaper and Less Complex Software Production Looks Like
Now, let’s be clear. Can you say MAKE ME MICROSOFT WORD BUT BETTER, or SOLVE THIS CLASSIC COMPSCI ALGORITHM IN A NOVEL WAY? No, you can’t, which will cause many to dismiss these technologies as toys. And they are toys in an important sense. They are “toys” in that they are able to produce snippets of code for real people, especially non-coders, that one incredibly small group would have thought trivial, and another immense group would have thought impossible. That. Changes. Everything.
How? Well, for one, the clearing price for software production will change. But not just because it becomes cheaper to produce software. In the limit, we think about this moment as being analogous to how previous waves of technological change took the price of underlying technologies—from CPUs, to storage and bandwidth—to a reasonable approximation of zero, unleashing a flood of speciation and innovation. In software evolutionary terms, we just went from human cycle times to that of the drosophila: everything evolves and mutates faster.
Here is one of our thought experiments: What if the cost of software production is following similar curves, perhaps even steeper curves, and is on its way to falling to something like zero? What if producing software is about to become an afterthought, as natural as explaining oneself in text? “I need something that does X, to Y, without doing Z, for iPhone, and if you have ideas for making it less than super-ugly, I’m all ears”. That sort of thing.
We can now revisit our earlier declining cost curves, and add software to the mix. What if the cost of producing software is set to collapse, for all the reasons we have discussed, and despite the internal Baumol-ian cost disease that was holding costs high? It could happen very quickly, faster than prior generations, given how quickly LLMs will evolve.
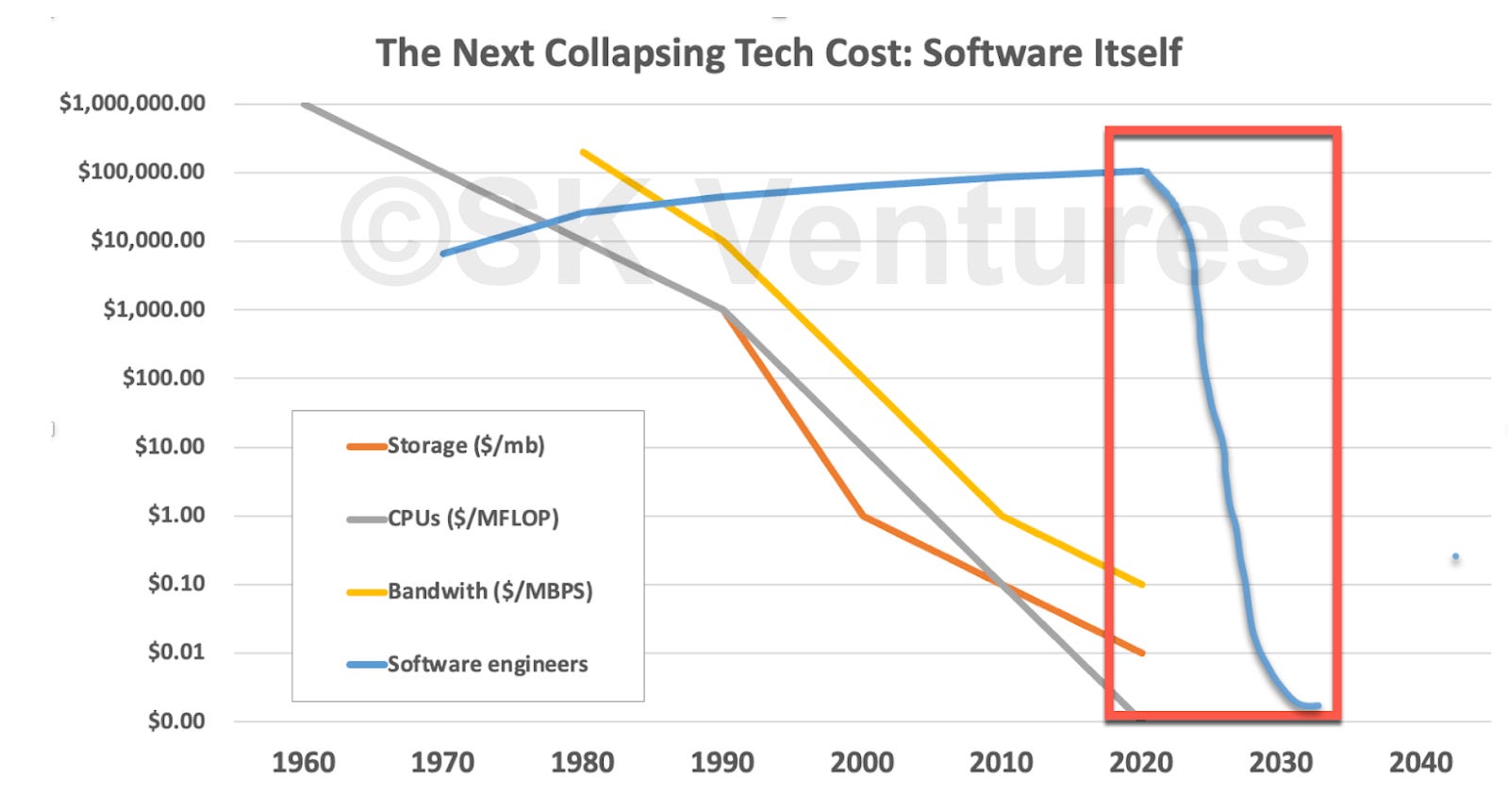
What does this all mean? We have nothing against software engineers, and have invested in many brilliant ones. We do think, however, that software cannot reach its fullest potential without escaping the shackles of the software industry, with its high costs, and, yes, relatively low productivity. A software industry where anyone can write software, can do it for pennies, and can do it as easily as speaking or writing text, is a transformative moment. It is an exaggeration, but only a modest one, to say that it is a kind of Gutenberg moment, one where previous barriers to creation—scholarly, creative, economic, etc—are going to fall away, as people are freed to do things only limited by their imagination, or, more practically, by the old costs of producing software.
This will come with disruption, of course. Looking back at prior waves of change shows us it is not a smooth process, and can take years and even decades to sort through. If we’re right, then a dramatic reshaping of the employment landscape for software developers would be followed by a “productivity spike” that comes as the falling cost of software production meets the society-wide technical debt from underproducing software for decades.
As We Pay Off Technical Debt, What Happens Next?
We have mentioned this technical debt a few times now, and it is worth emphasizing. We have almost certainly been producing far less software than we need. The size of this technical debt is not knowable, but it cannot be small, so subsequent growth may be geometric. This would mean that as the cost of software drops to an approximate zero, the creation of software predictably explodes in ways that have barely been previously imagined.
The question people always have at this point is, “So what app gets made?” While an understandable question, it is somewhat silly and definitely premature. Was Netflix knowable when Internet transit costs were $500,000/Mbps? Was Apple’s iPhone imaginable when screens, CPUs, storage and batteries would have made such devices the size of small rooms? Of course not. The point is that the only thing we know is that the apps and services will come. Without question. And you want to be there for it, investing in them from the initial wind rattling leaves in branching trees. In short, the greenfield in front of us now looks like the next great technology cycle, but one that far too many people simply aren’t seeing (as they remain focused on investing in current LLMs bolted on to anything currently living in the software wild).
Entrepreneur and publisher Tim O’Reilly has a nice phrase that is applicable at this point. He argues investors and entrepreneurs should “create more value than you capture.” The technology industry started out that way, but in recent years it has too often gone for the quick win, usually by running gambits from the financial services playbook. We think that for the first time in decades, the technology industry could return to its roots, and, by unleashing a wave of software production, truly create more value than its captures.